

GPT, T5, BERT, BART, CTRL: 1세대 언어모델
여기서 T는 transformer를 의미함
LLama: 최근 언어모델
Transformer
자연어의 세계는 트랜스포머 (2017) 이전과 이후로 나뉨
2017년의 Attention Is All You Need 제목의 논문으로부터 모든것이 시작되었음.
attention: 중요한 부분은 더 집중하고 중요하지 않은 부분은 덜 집중하자; 라는 개념에서 시작되었음.
문맥을 잘 이해하는 것이 중요. > 문맥을 이해하기 위해 문장 내에서 어떤 부분에 집중하고 어떤 부분에 덜 집중하면 될지를 해당 논문에서 다룸.
With transformers, 'Attention Is All You Need ' for context-understanding
즉, 다른 cnn, rnn 같은 architecture 를 붙이지 않고도 attention만으로도 모든게 가능하다고 말해서 특별한것.
2014 Neural Machine Translation by Jointly Learning to Align and Translate
Convolutional Sequence to Sequence Learning
2022) Transformers are eating Deep LEarning
단순히 text뿐 아니라, 다른 분야에서도 빛을 발하고 있는 중
그렇다면 Transformer는 왜 뛰어난 성능을 보이고 있는걸까?
- RNN, Transformer 등에서의 핵심은 문장의 컨텍스트를 얼마나 잘 이해하고 있는지가 매우 중요함.
- transformer가 RNN보다 뛰어난 이유는 context를 retrieval 하는 방식이 다르기 때문이다.

- 각자가 컨텍스트를 어떻게 판단하는지가 다름.
- RNN은 순차적으로 처리 > 즉, temoral vanishing gradients를 형성함.
- transformer는 눈에 띄는 단어들 사이의 관계를 빠르게 파악하는데 집중함. RNN에서 발생하는 문제점을 해결하기 때문에 1) input 길이에 상관없이 context 를 파악할 수 있고, 2) 안정적인 training (local minimal)에 빠지지 않게 됨,)
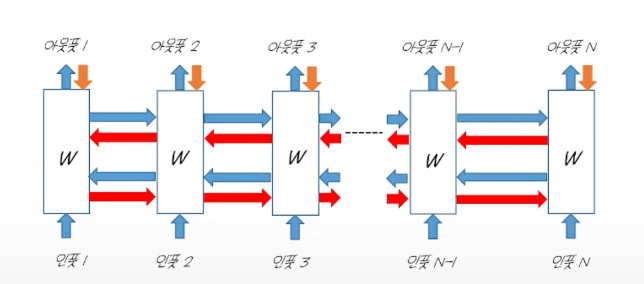
RNN
- RNN에서 temporal vanishing gradient 문제가 발생하는 이유는 recursive 구조로 인해 동일한 weight가 누적되어 곱해지기 때문이다.
- 문장을 읽듯 단어 하나하나를 순차적으로 처리함. 가중치 w가 계속 반복되어 적용되는 것을 볼 수 있음.


- w 행렬이 역전파 과정에서 문장의 길이만큼 반복적으로 곱해짐. 즉 w가 1보다 커지면 계속 곱해지면 무한대, w가 1보다 작다면 0에 근사하게 됨. (이때 0에 근사하게 되는 현상을 vanishing gradient라 함 / 반대 현상은 floating gradient)

- vanishing gradient는 레이어가 많아질수록 발생할 확률이 매우 많아짐.
- RNN은 순환구조로 인해 레이어의 깊이가 깊지 않아도 문장의 길이가 길다면 해당 문제에 직면하게 됨.
- 해당 문제가 발생하면 모델은 과거에 있었던 정보들을 잘 기억하지 못하게 됨.
- RNN이 순환구조를 포기하지 못했던 이유는 바로 어순 때문임. (언어에서는 순서가 매우 중요하기 때문)
RNN에서 temporal vanishing gradient 현상을 해결하기 위한 방법론들
1. Fixed-window backpropagation
- 역전파의 범위를 줄이는 것

2. Bidirectional RNN
- 과거 정보가 사라진다면 미래에서 과거로 정보를 역전달하는 방식
3. LSTM and GRU
- gate라는 스위치같은 개념을 도입하여 매 스텝마다 gradient를 적절하기 유지
- 그러나 얘네도 텍스트의 길이가 길어지면 답이 없음 temporal vanishing 생김
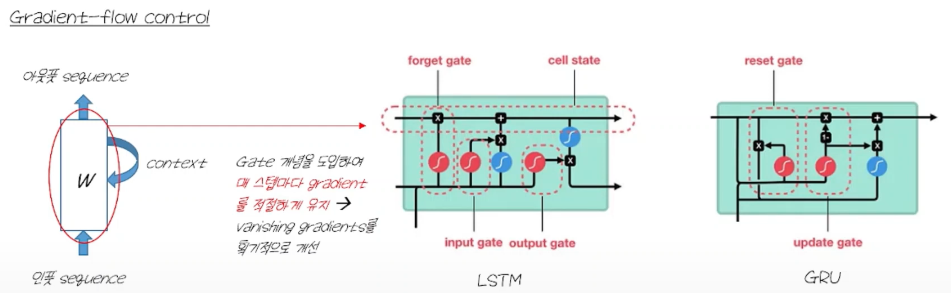
Transformer에서 temporal vanishing gradient 현상이 없는 이유
- 순환 구조가 없기 때문
- 즉, backpropagation 시 곱해지는 weight 들이 모두 다르기 때문
- 따라서, 메모리가 허락하는 한 input의 길이를 길게 해도 temporal vanishing gradients 현상이 사라짐.
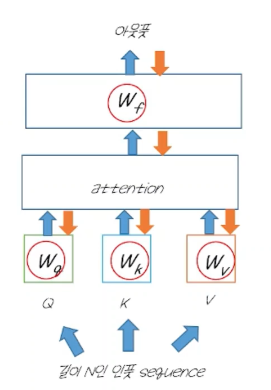
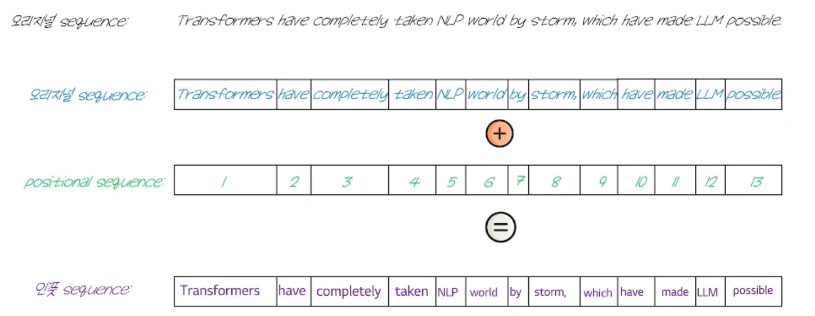
- 순환구조를 버려 어순에 대한 정보가 사라지기 때문에 positinal encoding 정보를 추가함.
- 원래 문장의 어순을 담은 특별한 변수를 추가
Transformer 동작과정
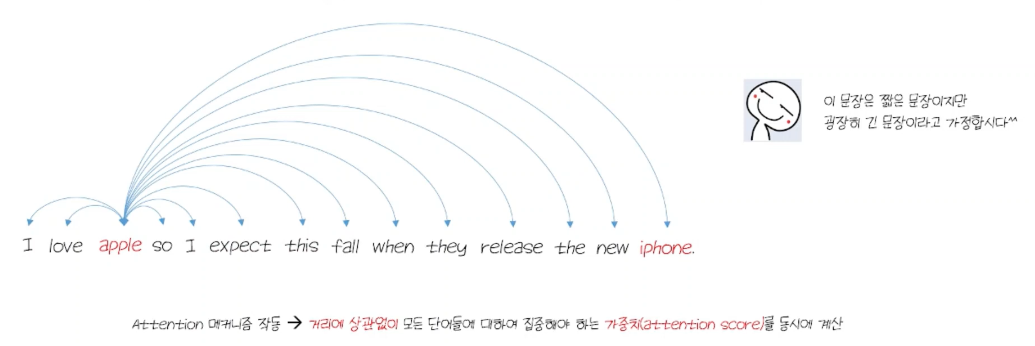
- 다른 단어들과의 친밀도를 모두 뽑아냄 (attention score)
- 트랜스포머를 이러한 attention score를 바탕으로 어떤 단어를 중점적으로 볼지 정함
- 병렬적으로 매우 빠르게 모든 단어에 대해서 파악.
출처: https://www.youtube.com/watch?v=lNuJ1nmeDs0&list=PLgqm0A83muLPAZ-SrHQyUYCEm3zXHx-xH&index=1
'전공 이론 공부 > 자연어처리' 카테고리의 다른 글
| Sequence to Sequence (0) | 2024.07.12 |
|---|---|
| 임베딩(Embedding)이란? (0) | 2024.07.09 |
| 텐서 조작 방법 (Tensor Operations) (0) | 2024.07.03 |
| BOW (Bag of Words) (0) | 2024.06.30 |
| 단어 빈도 그래프 (0) | 2024.06.25 |
전공 공부 기록 📘
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!

