

Motivation
- multiple input이 있을때 현재 상황을 가장 잘 풀어내는 정보들을 취합해서 하나의 숫자로(여저개) 만들어낼 수 있는가?
- 현재 번역을 하고 있는데 번역하고 있는 그 단어와 가장 잘 어울리는 단어는 무엇일까?
- 과거 기록을 가지고 추천해야한다면, 현재 그 사람의 정보와 가장 잘 어울리는 하나는 무엇일까? 등등
- sequence of information을 blending 해보는건 어떨까?: Attention을 관통하는 개념
- 복수개의 데이터를 가지고 있는데 일부분씩을 떼어서 섞었더니 전체적인 데이터 정보가 만들어진다면 blending이라고 말할 수 있지 않을까??
Query Vector가 있고, (우리가 관심있는애)
Multiple Vectors가 있음
반응성을 확인해서 위 둘을 섞어서 blended vector를 만든다.

NN에서 blending이란 두 벡터를 더한다느 것
summary the items using the 'importance of the items
attention: importance가 바로 attention score라고 말할 수 있다.
동작방식
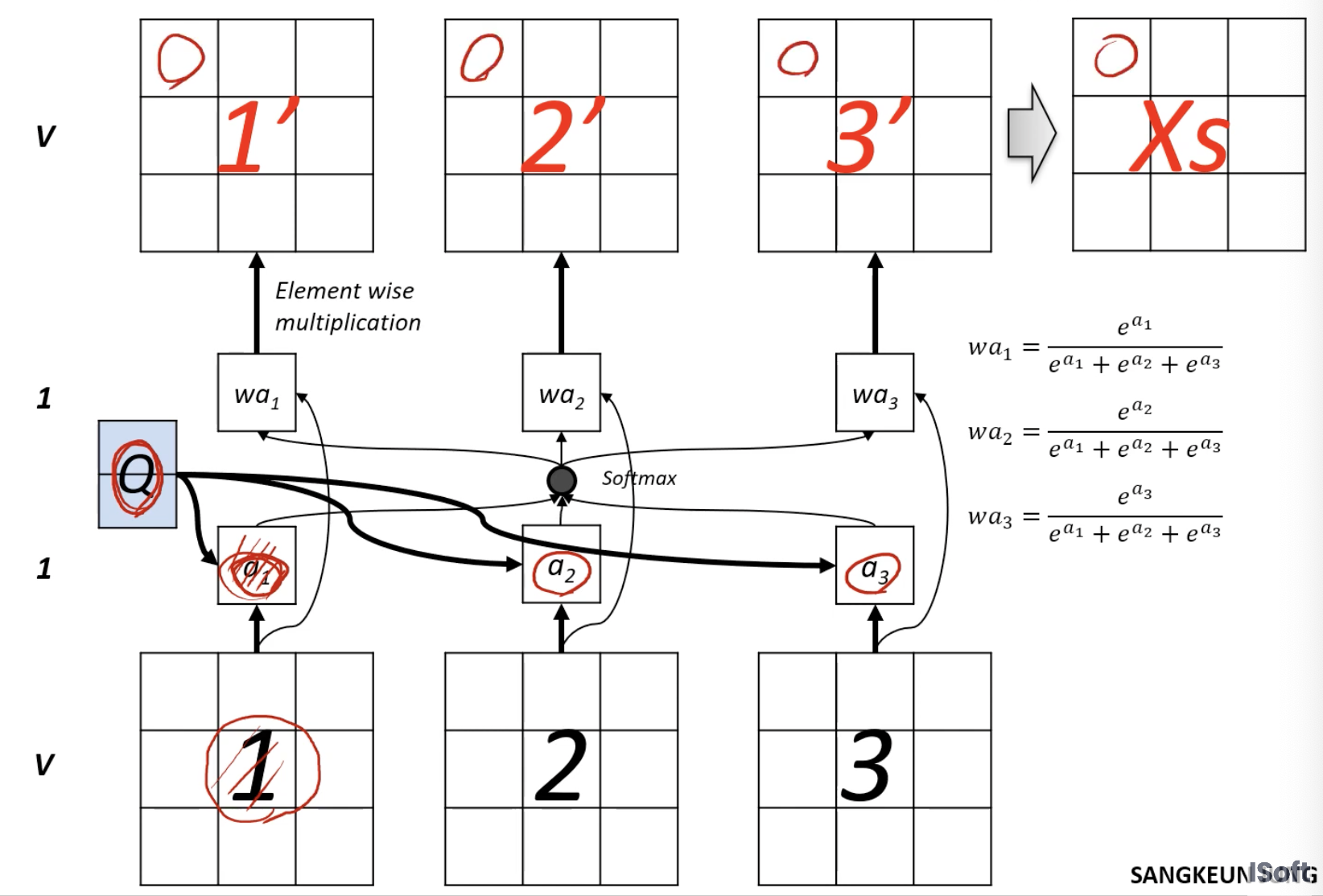
1. 데이터를 하나의 output으로 projection 시키는 A가 있다고 해보자.

2. softmax function으로 묶음 (모두 양수 나오고 더하면 1이 됨)

3. 새로운 값을 가지지만 똑같은 크기인 V가 만들어짐 (blending된것)


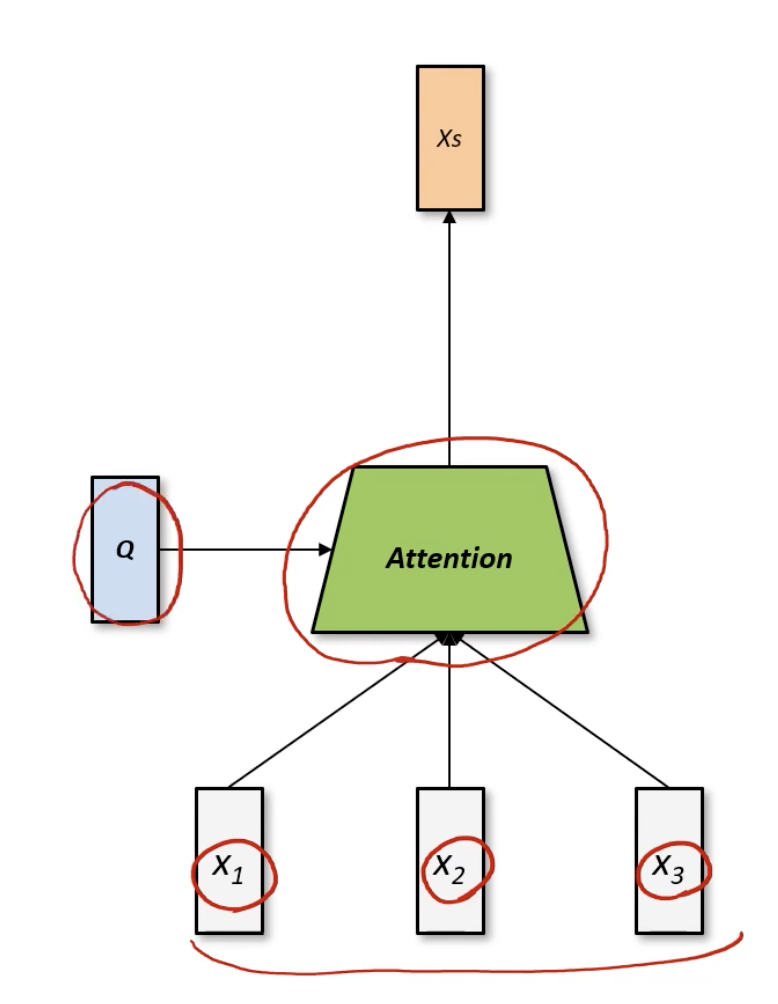
Query가 있는 Attention
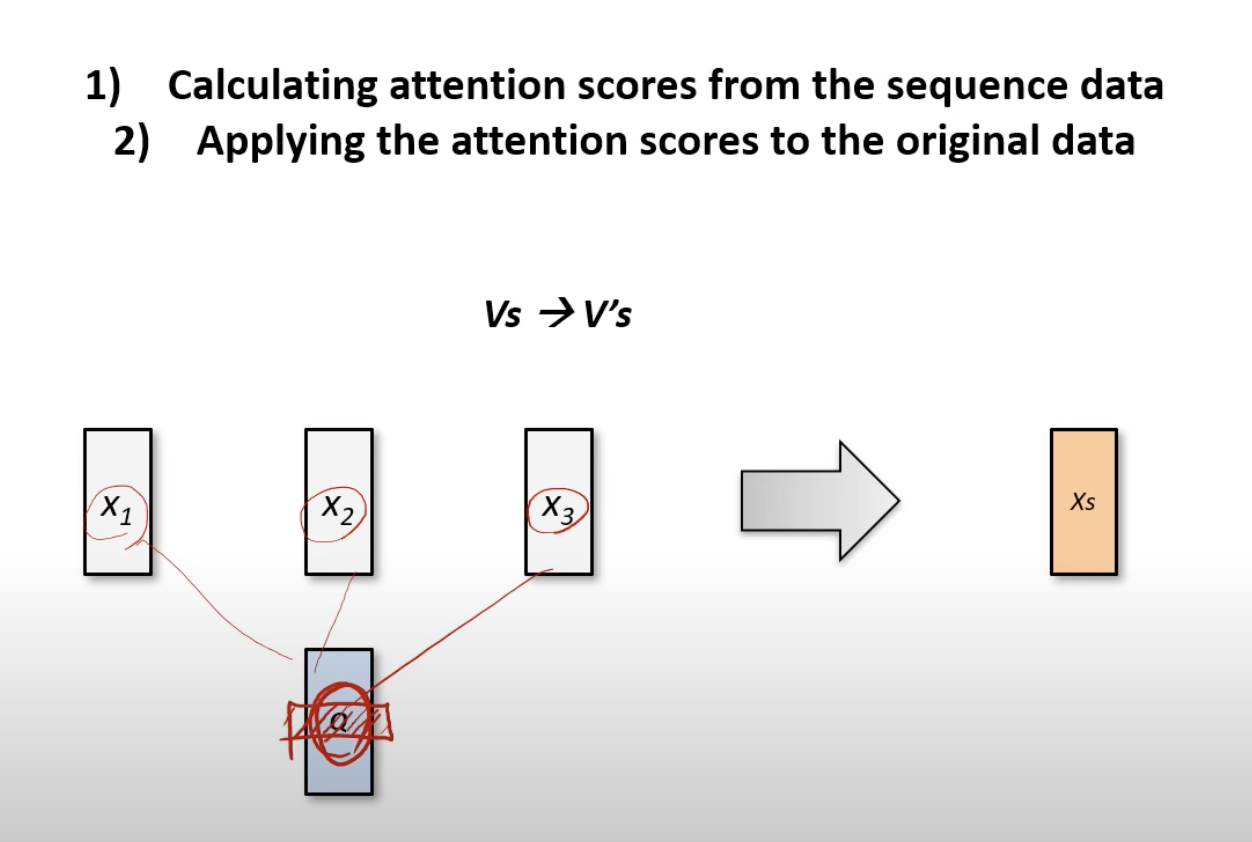
목표: Q와 가장 잘 반응해는 input data들을 모아서 blending하겠다!
1. 숫자를 얻어내~ a1, a2, a3
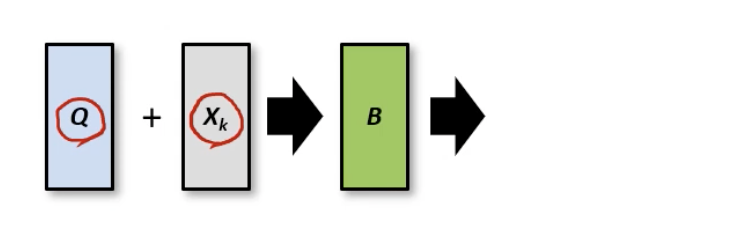
어떻게 Q라는 정보를 잘 녹여낼 수 있을까? 에 대해서 많은 방법론들이 존재함.
1. Additive Approach
- 반응성을 보는데 덧셈을 이용해보자
- Bahdanau attention
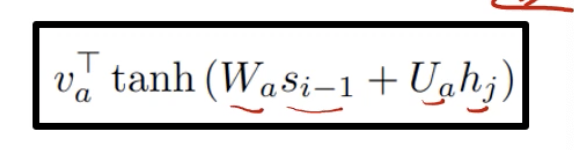
2. Multiplicative Approach
- 반응성을 보는데 곱셈을 이용해보자
- dot, general, concat
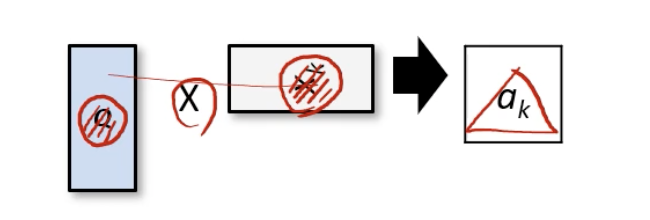
1) dot
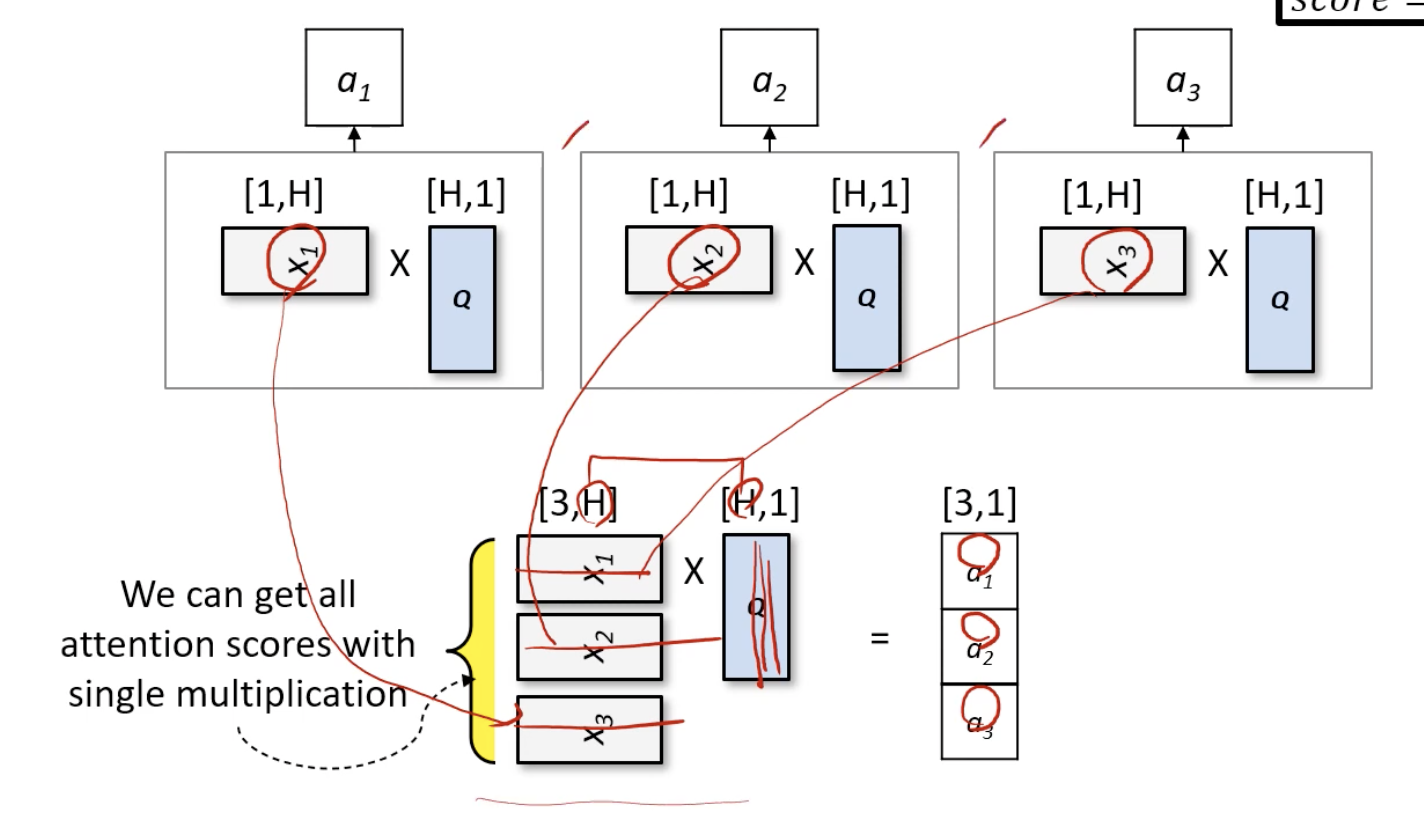
- for loop over multiple items N time
- It conducts N dot operation
- In optimized code, we do not use this approach
- multiple item이 많아질수록 연산이 많아질텐데 이것을 dot approach 하나만으로 처리 가능
2) general
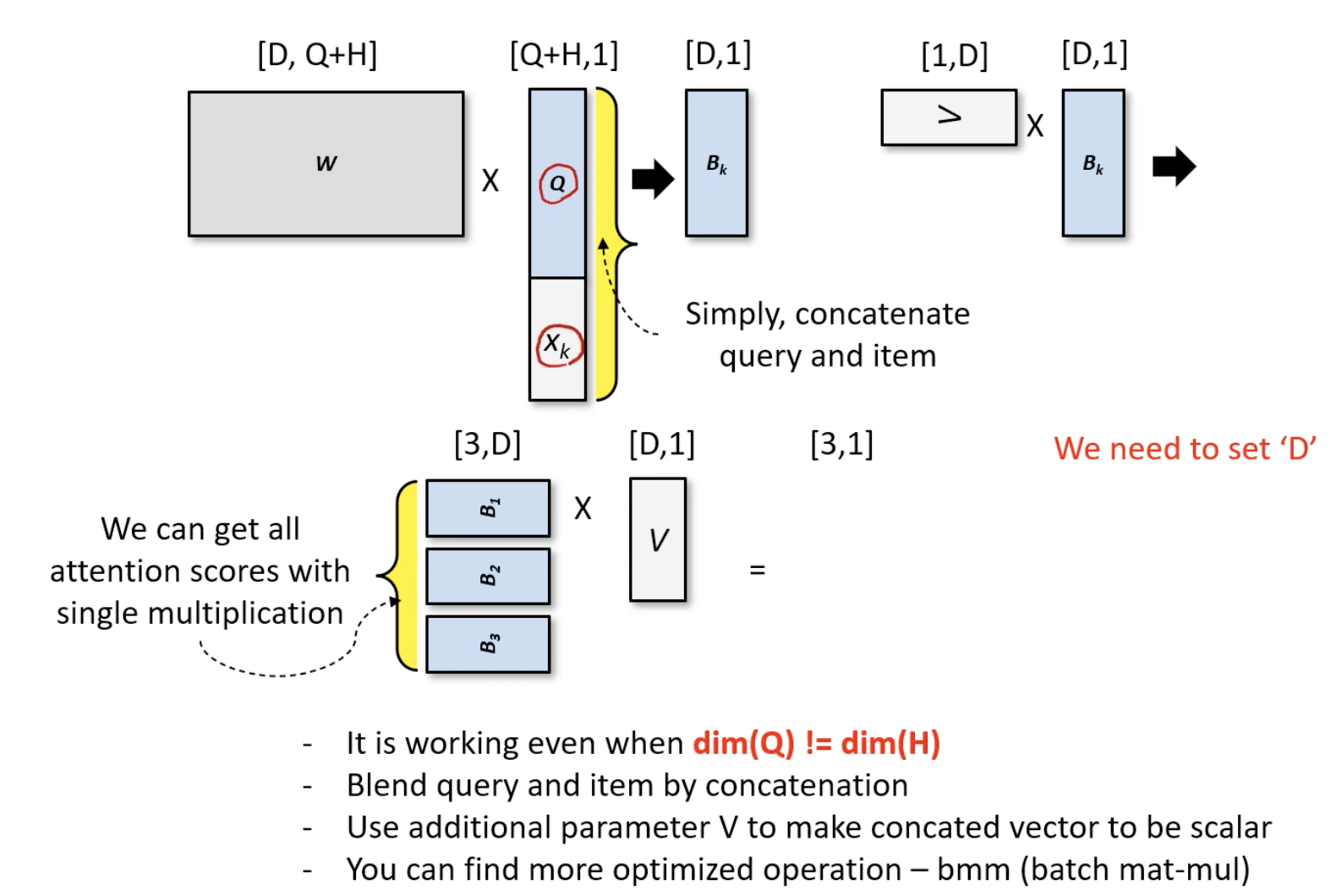
3) concat
Attention Mechanism이 어떻게 Sequence to Sequence(encoder/decoder 구조)에 쓰이는지?
- "서울역 근처 스타벅스로 가자"라는 말이 있을 때, 어떤 단어에 중점을 맞춰서 번역을 해야하는가?
- 어떤 단어를 중심으로 blending해야하는가?
- 즉, decoding이 이루어질때마다 encoding 과정에서 blending할 필요가 있음.
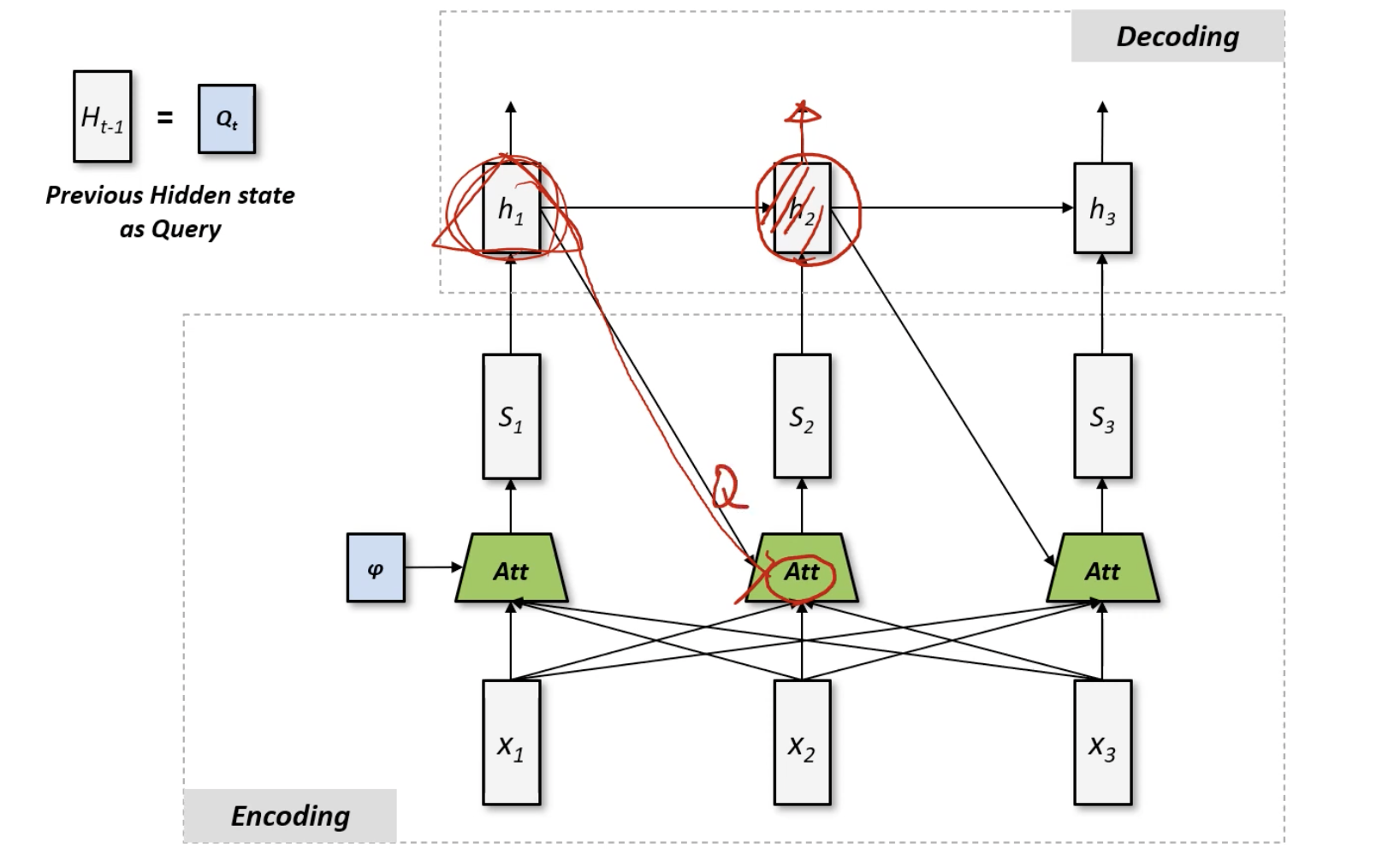
- 옛날거가 쿼리처럼 들어옴 (최초모델)
- input 개수와 output 개수가 다를때는 어떻게 해야할까?
- 출력 개수가 생성될 때마다 attention이 새롭게 인코딩 인풋 데이터를 그때그때봐서 그때마다 블렌딩해서 출력
- sequential 하지만 sequential 데이터가 중요하지 않음 (global함, selective)
출처: https://www.youtube.com/watch?v=VYxuGOs_Y4o&list=PL3BTODKVj3plw2dm1nDn1RMa9Fs-j5QoY&index=5
'전공 이론 공부 > 자연어처리' 카테고리의 다른 글
| Transformer란? (0) | 2024.07.13 |
|---|---|
| Sequence to Sequence (0) | 2024.07.12 |
| 임베딩(Embedding)이란? (0) | 2024.07.09 |
| Transformer v.s. RNN (0) | 2024.07.09 |
| 텐서 조작 방법 (Tensor Operations) (0) | 2024.07.03 |
전공 공부 기록 📘
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


